
一个进程的诞生(bushi)

一个进程的诞生(bushi)
chengzi打开电脑手机,一个个app眼花缭乱地出现在程序坞里,外卖app,打车app,王者荣耀……在使用这些应用方便你的生活的同时,你是否好奇过这一串串代码是通过怎样的流程变成眼前的程序的呢?
程序的编译,链接与装入
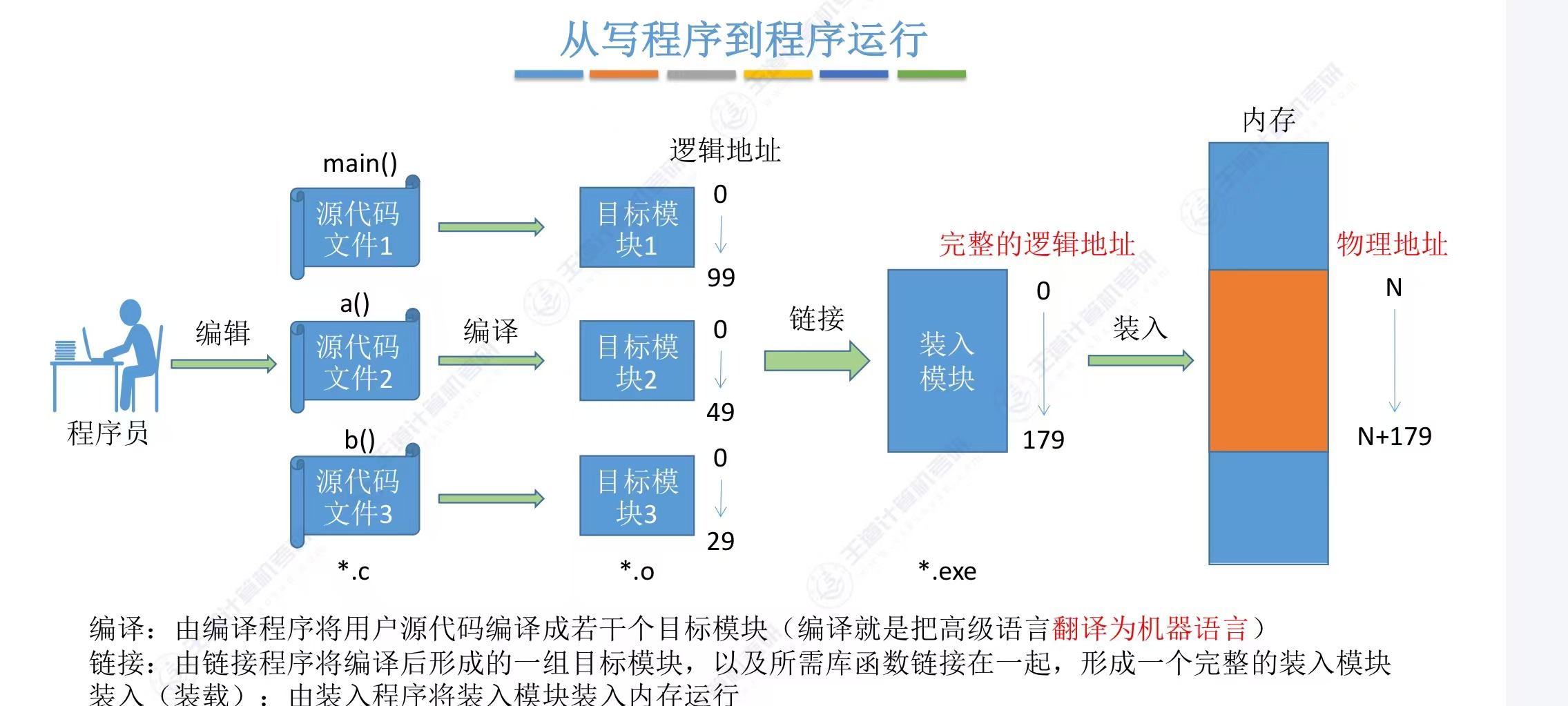
当程序员编写好代码,源代码文件也就形成了。大到成千上万行,小到“hello world”,都是一个个源代码文件。经过编译程序将源代码编译成若干个目标模块,编译过程将高级语言翻译为机器语言,即生成CPU能够识别的指令。再由链接程序将编译后形成的一组目标模块,以及所需库函数链接在一起,形成一个完整的装入模块(可执行文件)。链接过程将各个目标模块整合为一个整体,以便后续装入内存执行。这就是程序执行的第一步。
 [图源王道操作系统讲义]
[图源王道操作系统讲义]
可以看到,当编辑好不同的模块时,其逻辑地址都是独立的,从0开始。而链接的工作就是形成一个完整的逻辑地址。链接主要分为三种:静态链接,装入时动态链接,运行时动态链接,现在较为常用的是第三种。
运行时动态链接是指在程序运行时,由操作系统的装载程序(如Windows的Loader或Linux的ld.so)负责将程序的各个模块加载到内存中,并解析它们之间的引用关系。比如当程序需要调用某个库函数时,操作系统会查找并加载相应的动态链接库,然后通过符号表找到函数的入口地址,并进行跳转执行。
先讲讲静态链接。静态链接本质上就是将源文件a.c,b.c等文件打包成.o文件的集合,一个.a文件,再和要调用它们的.o文件(比如main.o)一起进行链接,形成一个可执行文件。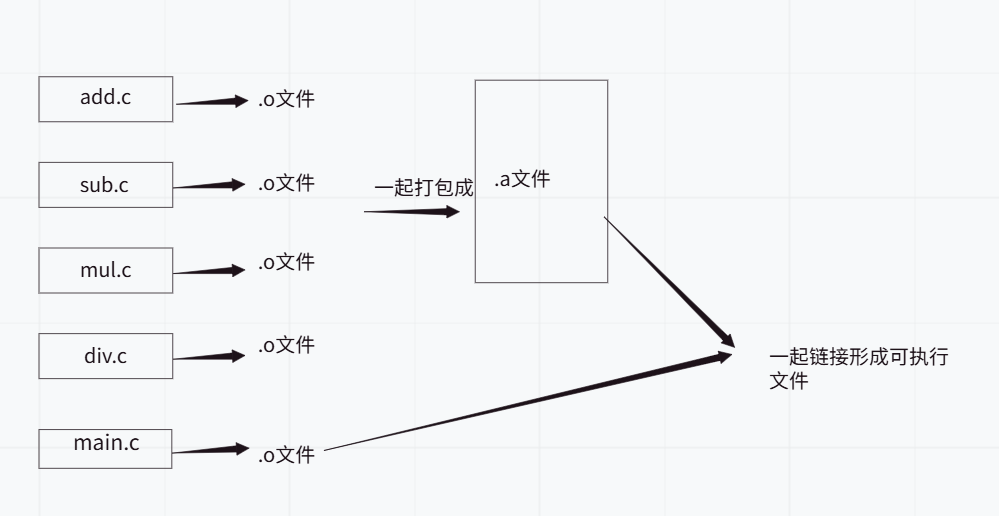
例如在Linux 环境下,创建一个简单的 mymath 库并在 main 函数中进行调用:
- 创建
mymath库的源文件
首先创建add.c文件和sub.c文件,代码如下:
1 | // add.c |
- 创建头文件
接着创建对应的头文件用于声明库中的函数,以便在其他源文件中可以正确调用这些函数。代码如下:
1 | // mymath.h |
- 编译生成静态库(
.a文件)
编译
add.c文件生成目标文件(.o文件):
在命令行中执行以下命令:1
2gcc -c add.c -o add.o
gcc -c sub.c -o sub.o //-c 选项表示只进行编译而不进行链接操作。将目标文件打包成静态库:
使用ar命令将目标文件打包成静态库,执行如下命令:1
ar rcs libmymath.a add.o sub.o
ar是用于创建、修改和提取归档文件(在 Linux 下静态库本质上就是一种归档文件)的工具,rs代表replace and create,s选项表示生成索引以加快库的链接速度。最终生成的静态库文件名为libmymath.a。
- 创建使用库的主程序文件
创建main.c文件来调用mymath库中的函数,代码如下:
1 | // main.c |
- 编译并链接主程序与库文件
在命令行中执行以下命令来编译并链接main.c和libmymath.a库:1
gcc main.c -L. -lmymath -o main
-L.选项告诉编译器在当前目录(.表示当前目录)下查找库文件,-lmymath表示链接名为mymath的库(按照约定,编译器在链接时会自动在库名前添加lib前缀并寻找对应的.a或.so文件等),-o main选项指定生成的可执行文件名为main。
最后,运行生成的可执行文件 main:
1 | ./main |
就可以看到程序输出计算的结果了。
而动态链接在程序编译时,并不会把库文件的代码和数据复制到可执行文件中,而是在程序运行时,当需要调用库中的函数或使用库中的数据时,才动态地加载库文件,并将所需的代码和数据链接到程序的内存空间中,这点和静态链接是不同的。
如果想创建动态共享库(.so 文件),步骤和静态相比稍有不同,大致流程如下:
- 创建动态共享库
编译生成位置无关代码(PIC)的目标文件:
执行命令:1
2gcc -fPIC -c mymath.c -o add.o
gcc -fPIC -c mymath.c -o sub.o-fPIC(Position Independent Code)选项用于生成位置无关的代码。创建动态共享库文件:
使用以下命令:1
gcc -shared -o libmymath.so add.o sub.o
-shared选项告诉编译器创建一个动态共享库,最终生成libmymath.so文件。
- 使用动态共享库
- 编译主程序并链接动态共享库:
执行命令:在运行程序时,需要确保动态库的路径能被系统找到,可以通过设置1
gcc main.c -L. -lmymath -o main
LD_LIBRARY_PATH环境变量来指定动态库所在路径,例如(假设当前目录就是动态库所在目录,所以以.来代表该路径):1
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:.
补充:在Linux系统中,环境变量是一种用于存储系统或用户相关配置信息的机制。这些变量可以被系统中的各个程序访问,并且它们的值会影响程序运行时的行为。例如,PATH 环境变量就指定了系统在哪些目录下去查找可执行程序,当在终端输入命令时,系统会根据 PATH 中设定的目录顺序去查找对应的可执行文件来执行。
LD_LIBRARY_PATH 则是专门用于指定动态链接库搜索路径的环境变量。当一个程序在运行过程中需要加载动态链接库时,系统就会按照一定规则去查找这些库文件。
或者直接将动态库拷贝到系统默认的库搜索路径下(如 /usr/lib 等,需要管理员权限来操作)。
1 | sudo cp libmymath.so /usr/local/lib |
经过链接,程序也就形成了一个具备完整地址的源文件。
然后执行装入,顾名思义,装入就是将一整个模块装入内存运行。
装入也有三种类型:
绝对装入
在编译时,程序员必须知道目标程序在内存中的起始地址,并生成与这个地址绑定的绝对代码。装入程序按照装入模块中的地址,将程序和数据装入内存。
这种方式仅适用于单道程序环境,因为在这种环境下,内存中只有一个程序在运行,内存位置是固定的。
可重定位装入(静态重定位)
编译时,生成的目标代码地址是相对地址,即相对于某个基准点的偏移量。
装入时,装入程序根据内存的当前情况,将相对地址转换为绝对地址。这一步通过内存管理部件(MMU)实现,此机制对用户是完全透明的。
如果装入后的内存空间不够,可以通过紧凑(将各个程序在内存中“搬家”,使它们紧凑地排列在一起)或覆盖(将程序划分为多个段,每次只将需要执行的段调入内存)等技术来解决。
动态运行时装入(动态重定位)
程序在内存中的起始地址在编译时和装入时都不确定,而是在程序执行时才确定。
装入程序将程序装入一个连续的内存区域,并设置一个重定位寄存器,用于存放程序的起始地址。
程序执行时,通过重定位寄存器和相对地址计算出实际的内存地址。
静态重定位与动态重定位区别
静态重定位是在程序装入内存时,一次性完成逻辑地址到物理地址的转换,之后程序在运行过程中不再改变这些地址。这种方式需要预先分配全部所需内存空间,并且程序在运行期间不能移动或再申请内存空间。而动态重定位则是在程序运行过程中,每当需要访问内存时,才进行逻辑地址到物理地址的转换。当程序装入内存时,只装入相对地址,不立即进行地址转换。在程序执行过程中,通过硬件地址转换机构(如重定位寄存器)和相应的软件支持,动态地完成地址转换。例如执行每条指令都需要从逻辑地址去算出它的物理地址,链接形成的逻辑地址加上规定寄存器(常用重定位寄存器,基址寄存器)的值就会得到真实的物理地址。
TIPS:物理地址是内存物理单元的地址,所有进程运行时需要的指令和数据都需要通过物理地址从内存中取。而逻辑地址(不太严谨的话,可以将逻辑地址,虚拟地址,相对地址画等号)是在链接时从0单元开始编址的空间,是虚拟的。
初始化
此时程序已经进入了内存,具备进程(进行中的程序)的雏形。操作系统为每个新进程创建一个PCB,这是操作系统管理和跟踪进程的核心数据结构。
在Linux系统里,task_struct就是PCB。task_struct是Linux内核中的进程描述符,用于存储与进程相关的信息。它是感知进程存在的唯一实体,包含了进程的各种属性和状态信息。每个进程在内核中都有一个对应的task_struct结构体。这个结构体包含了进程的标识符(PID)、进程状态、进程权限、进程调度信息、信号处理信息、内存管理信息(如指向mm_struct的指针)等。
在task_struct结构体中,有一个名为mm的字段,它是一个指向mm_struct结构体的指针。这个字段用于关联进程描述符和进程的内存描述符。对于普通的用户进程来说,mm字段指向该进程的虚拟地址空间的用户空间部分;而对于内核线程来说,这个字段为NULL,因为内核线程没有独立的内存地址空间(它们使用内核的地址空间,并且所有进程关于内核的映射都是一样的)。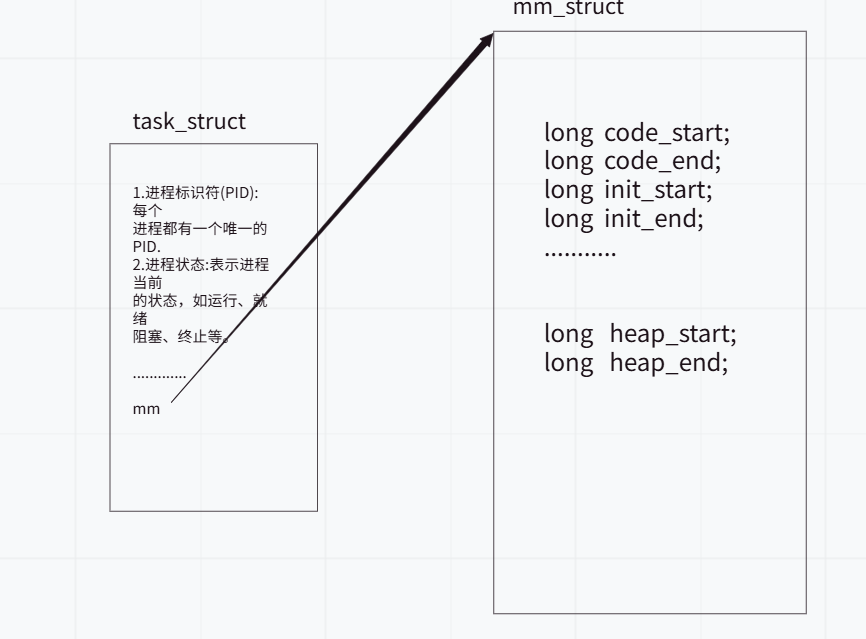
如图,mm_struct包含了代码段,数据段,堆栈等区域的地址信息。
mm_struct是Linux内核中的内存描述符,用于描述进程的虚拟地址空间。它包含了与进程内存管理相关的各种信息,如进程的页表、内存区域的链表(通过vm_area_struct结构体描述)、内存映射的基地址和结束地址(如上图展示)、进程的内存使用情况统计等。
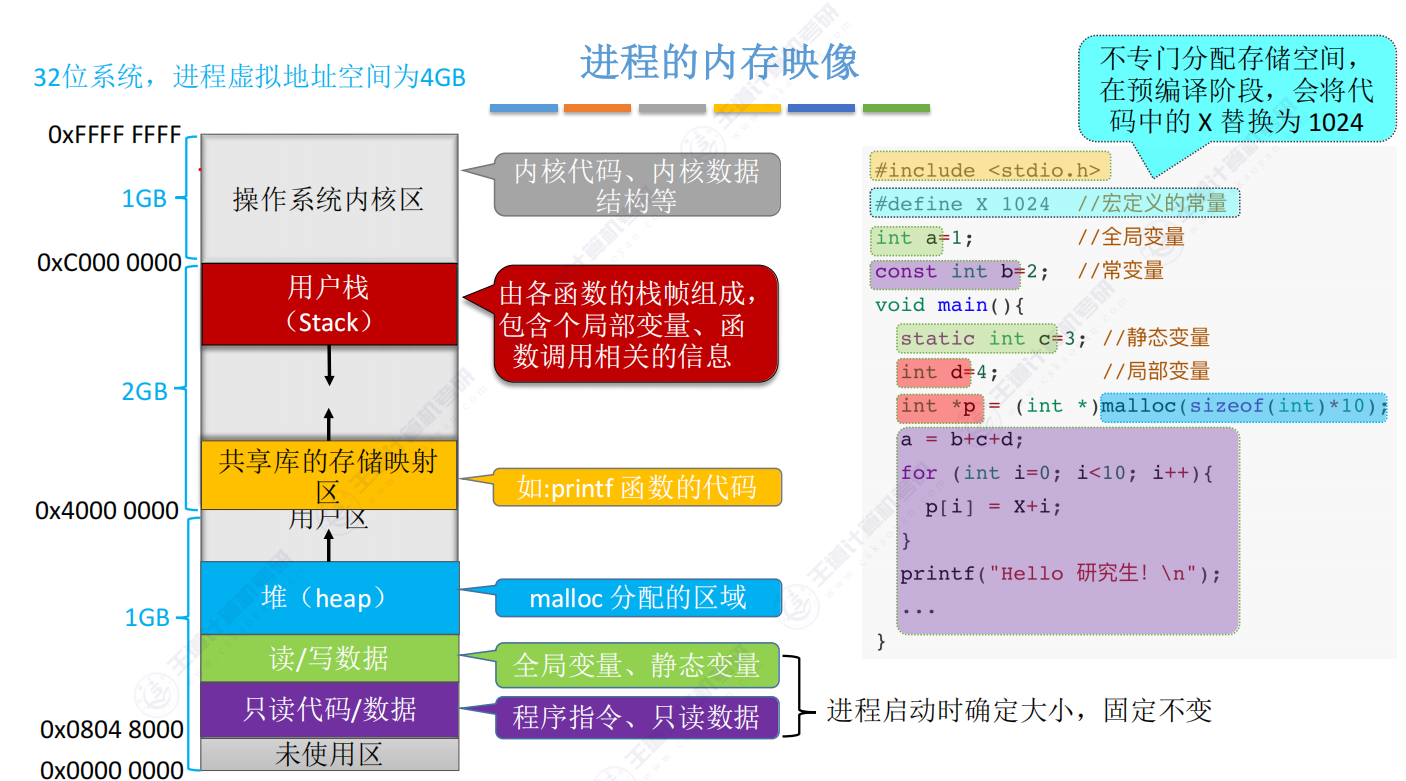
虚拟地址空间
进程的虚拟地址空间是地址空间的一个实例,特定于每个运行的进程。它是操作系统提供的虚拟内存管理的核心组成部分,用于将进程的数据和指令存放在内存中,并提供内存保护、地址映射、隔离等功能。每个进程的地址空间在逻辑上独立,允许多个进程并发执行,并且它们各自拥有自己的地址空间。
进程地址空间用于描述一个正在运行的进程在内存中的布局和管理方式。每个进程都有其自己的地址空间,它是虚拟内存的抽象表示,允许进程访问物理内存上的数据和指令。
本质上,进程地址空间就是在描述一个进程的可视范围的大小。同时在空间内必须要进行区域的划分。
进程地址空间通常包括以下组成部分:
代码段(Text Segment):也称为可执行段,包含进程的可执行指令。这是程序的机器代码,通常是
只读的,因为它应该在运行时不被修改。
数据段(Data Segment):用于存储进程的全局和静态变量。这包括初始化的全局变量和静态变量,通常是可读写的。
堆(Heap):用于动态分配内存,通常在运行时通过函数(如malloc和free)来进行内存分配和释放。堆的大小通常是可变的,取决于进程的需求。
栈(Stack):用于存储函数调用的局部变量和函数的调用信息。栈是一个后进先出(LIFO)数据结构,用于跟踪函数的调用和返回。栈的大小通常是固定的或者由操作系统动态管理。
堆栈区域之间的未映射空间(Unmapped Area Between Heap and Stack):这是两者之间的空闲区域,用于防止堆和栈之间的溢出。
内核空间(Kernel Space):这是由操作系统控制的部分内存,包含操作系统内核的代码和数据。用户进程不能直接访问内核空间,而必须通过系统调用来请求内核执行操作。
 [图源王道操作系统讲义]
[图源王道操作系统讲义]
总结:task_struct就是Linux里的PCB,负责管理进程的运行。而在task_struct中存在一个mm字段指向mm_struct,其一个功能就是保存当前进程的虚拟地址空间的地址信息(内存映像)。
这里的虚拟地址和链接时形成的逻辑地址又有区别。
进程的虚拟地址空间是操作系统为每个进程分配的一个独立的、连续的内存地址范围。它包含了进程的代码段、数据段、堆、栈等各个部分。虚拟地址空间的主要目的是提供内存隔离和保护,确保每个进程只能访问自己的内存空间,防止进程间相互干扰。
而链接时形成的逻辑地址是程序在编译或链接时由编译器或链接器生成的,用于在程序的运行过程中定位数据或指令。它并不直接对应物理内存中的实际位置,而是经过一系列转换后,才能映射到物理地址上。逻辑地址的主要作用是提供一个统一的、与物理内存无关的地址空间,简化编程工作。
每个进程的虚拟地址空间是独立的,且通常远大于物理内存的大小。操作系统通过虚拟内存技术(如分页和分段)将虚拟地址映射到物理地址上,实现内存的动态分配和访问控制。逻辑地址是程序内部的地址表示方式,它并不直接映射到物理地址上。在程序执行过程中,操作系统或硬件会将逻辑地址转换为物理地址,以实现数据的实际访问。
TIPS:其实没必要太过纠结虚拟地址和逻辑地址的本质区别,想要深究就得多研读《深入理解linux内核》这样的书籍。
创建完PCB,操作系统还会为进程分配额外的内存空间,如堆栈、数据区等。根据进程的初始执行需求,设置CPU寄存器的内容,如堆栈指针、指令指针等。如果进程是由另一个进程(父进程)创建的,操作系统会建立父子进程之间的关系,包括进程间的通信机制(如管道、消息队列等)和信号传递机制。
至此,一个基本的进程也就创建完成。每个进程的地址空间都是虚拟的,它将虚拟地址映射到物理内存上,这一步由操作系统的内存管理单元(MMU)来完成。MMU负责将虚拟地址转换为物理地址(中间会用到页表),同时实现了内存保护和隔离,确保一个进程在执行时无法访问或干扰其他进程的地址空间。
虚拟地址到物理地址的映射
等待施工。。。。









